微服务之SpringCloud
1、架构的演进
单体架构->集群:负载均衡 -> 分布式服务 -> SOA架构 ->微服务
2、微服务
特性:
- 完全独立的一个最小个体。(可以独立运行)
- 个体与个体之间,通过远程调用进行访问。例如:基于RESTFul风格的。
- 通过注册中心,将不同个体可以进行整合。
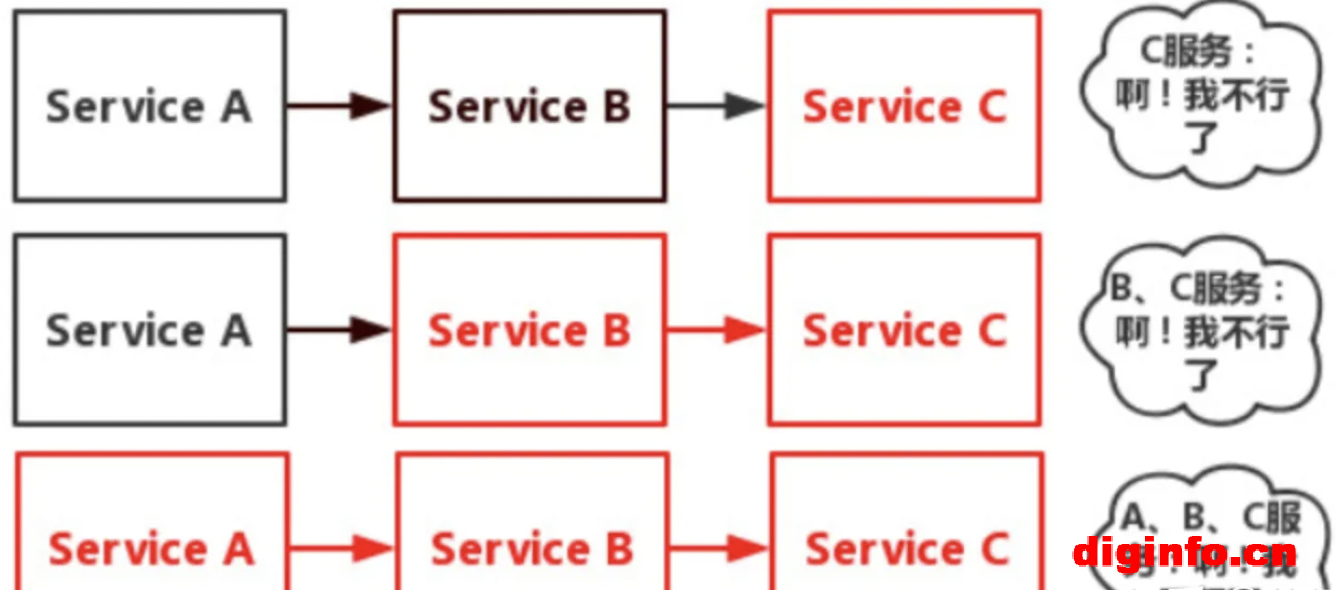
服务雪崩:
服务雪崩:在整条链路的服务中,一个服务失败,导致整条链路的服务都失败的情形。
存在整条链路服务(Service A、Service B、Service C)
Service A 流量突然性增加,导致Service B 和Service C 流量也增加。
Service C 因为抗不住请求,变得不可用。导致Service B的请求变得阻塞。
当Service B的资源耗尽,Service B就会变得不可用。
服务熔断:
当下游的服务因为某种原因突然变得不可用或响应过慢,上游服务为了保证自己整体服务的可用性,不再继续调用目标服务,直接返回,快速释放资源。如果目标服务情况好转则恢复调用。
最开始处于closed状态,一旦检测到错误到达一定阈值,便转为open状态;
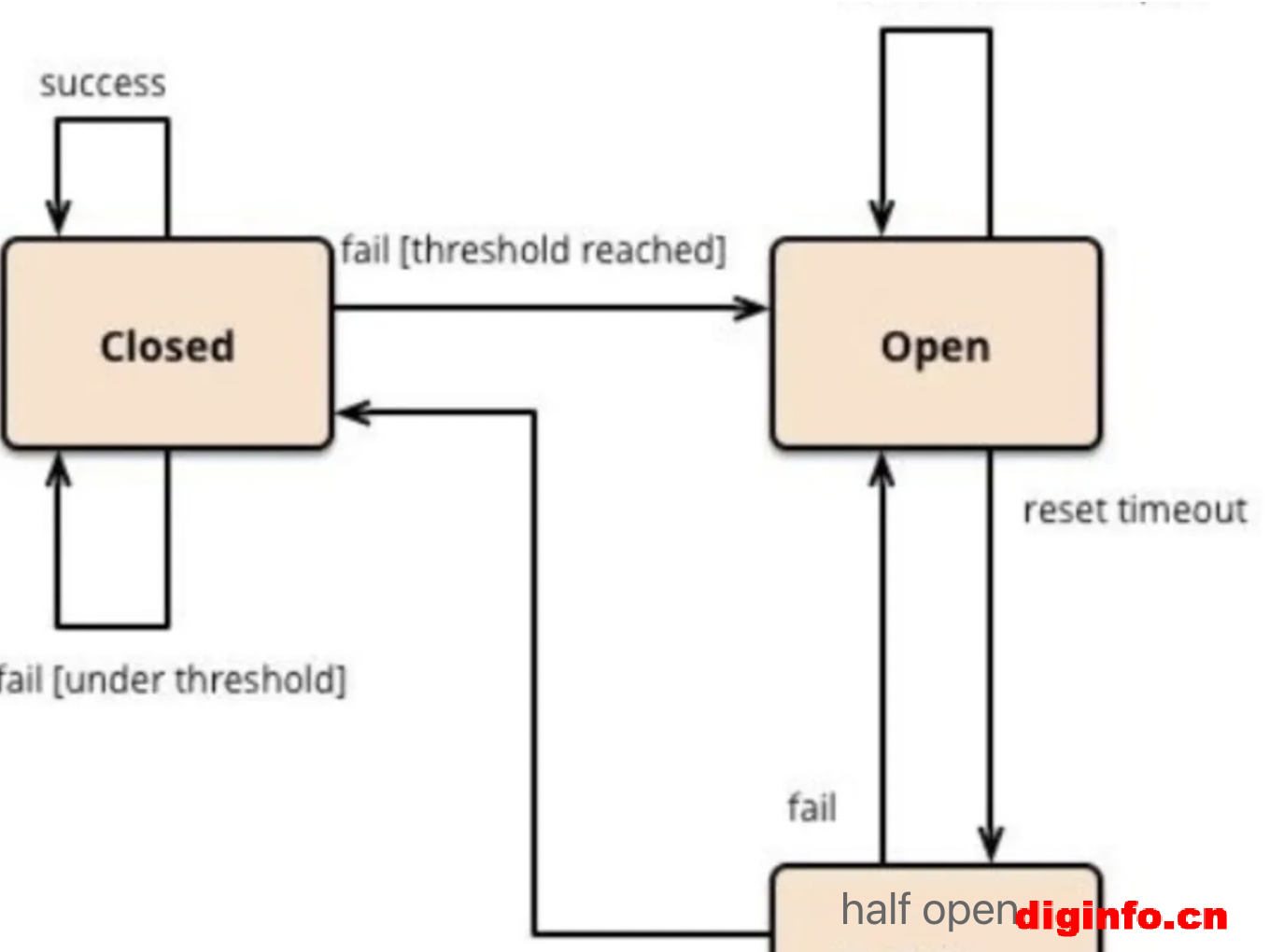
这时候会有个 reset timeout,到了这个时间了,会转移到half open状态;
尝试放行一部分请求到后端,一旦检测成功便回归到closed状态,即恢复服务;
服务降级:
当下游的服务因为某种原因响应过慢,下游服务主动停掉一些不太重要的业务,释放出服务器资源,增加响应速度!
当下游的服务因为某种原因不可用,上游主动调用本地的一些降级逻辑,避免卡顿,迅速返回给用户!
熔断和降级的区别:
服务降级有很多种降级方式!如开关降级、限流降级、熔断降级!
服务熔断属于降级方式的一种!
当发生下游服务不可用的情况,熔断和降级必定是一起出现。
服务降级大多是属于一种业务级别的处理,熔断属于框架层级的实现。
开关降级
在配置中心配置一个开关(变量),在配置中心更改开关,决定哪些服务进行降级。
3、什么是SpringCloud
Spring Cloud 是一系列框架的集合,它利用Spring Boot的开发便利性,简化了分布式系统开发,如:服务注册、服务发现、配置中心。消息总线、负载均衡、熔断器、数据监控等。
Spring Cloud 主要贡献者是Netflix,也就是Spring Cloud是对Netflix贡献的框架的二次封装或优化。
通俗的讲,SpringCloud就是用于构建微服务开发和治理的框架集合。
SpringCloud主要涉及的组件包括:
- Eureka:服务注册中心,用于管理服务
- Ribbon:负载均衡(集群)
- Hystrix:熔断器,能够防止服务的雪崩效应。
- Zuul:服务网关,提供路由转发、请求过滤等功能。
- Feign:服务调用,简化Http接口的调用。
4、Eureka注册中心
4.1、单个Eureka服务
- Eureka:就是服务注册中心,用于管理所有注册服务。
- 班级服务,服务的提供者,启动后向Eureka注册自己地址,方便服务调用方获取。
- 学生服务,服务的调用者,定期从eureka注册中心中获得服务列表。
- 心跳(续约):提供者定期通过http方式向Eureka刷新自己的状态。
当开发大型项目时,服务的提供方和服务的调用方,将会非常庞大,管理服务的成本将几何倍的增长。
Eureka将负责服务的注册、发现、状态监控。
注册:Eureka负责管理、记录服务提供者的信息
发现:服务调用者无需自己寻找服务,而是把自己的需求告诉Eureka,然后Eureka会把符合你需求的服务告诉你
监控:服务提供方与Eureka之间通过“心跳”机制进行监控,当某个服务提供方出现问题,Eureka自然会把它从服务列表中剔除
4.2、Eureka集群
高可用
多个Eureka Server之间也会互相注册为服务,当服务提供者注册到Eureka Server集群中的某个节点时,该节点会把服务的信息同步给集群中的每个节点,从而实现数据同步。因此,无论客户端访问到Eureka Server集群中的任意一个节点,都可以获取到完整的服务列表信息。
所谓的高可用注册中心,其实就是把EurekaServer自己也作为一个服务进行注册,这样多个EurekaServer之间就能互相发现对方,从而形成集群
服务提供者配置:
务提供者要向EurekaServer注册服务,并且完成服务续约等工作。
服务注册
服务提供者在启动时,会检测配置属性中的:eureka.client.register-with-erueka=true参数是否正确,事实上默认就是true。如果值确实为true,则会向EurekaServer发起一个Rest请求,并携带自己的元数据信息,完成注册操作。
服务续约
在注册服务完成以后,服务提供者会维持一个心跳(定时向EurekaServer发起Rest请求),告诉EurekaServer:“我还活着”。这个我们称为服务的续约(renew);
有两个重要参数可以修改服务续约的行为:
eureka:
client:
lease-renewal-interval-in-seconds: 5 #服务续约(renew)的间隔,默认值90秒
lease-expiration-duration-in-seconds: 10 #服务失效时间,默认为30秒
lease-expiration-duration-in-seconds:服务失效时间,默认值90秒
lease-renewal-interval-in-seconds:服务续约(renew)的间隔,默认为30秒
也就是说,默认情况下每个30秒服务会向注册中心发送一次心跳,证明自己还活着。如果超过90秒没有发送心跳,EurekaServer就会认为该服务宕机,会从服务列表中移除,这两个值在生产环境不要修改,默认即可。
但是在开发时,这个值有点太长了,经常我们关掉一个服务,会发现Eureka依然认为服务在活着。所以我们在开发阶段可以适当调小。
server:
port: 8080
spring:
application:
name: service
eureka:
client:
service-url: #注册中心位置
defaultZone: http://localhost:10086/eureka/
instance: #web页面显示效果和访问路径
instance-id: ${spring.application.name}:${spring.cloud.client.ip-address}:${server.port}
prefer-ip-address: true
lease-renewal-interval-in-seconds: 5 #5秒一次心跳
lease-expiration-duration-in-seconds: 10 #10秒及过期注册中心优化:失效剔除和自我保护:
失效剔除:有些时候,我们的服务提供方并不一定会正常下线,可能因为内存溢出、网络故障等原因导致服务无法正常工作。Eureka Server需要将这样的服务剔除出服务列表。因此它会开启一个定时任务,每隔60秒对所有失效的服务(超过90秒未响应)进行剔除。
自我保护:我们关停一个服务,就会在Eureka面板看到一条警告:
这是触发了Eureka的自我保护机制。当一个服务未按时进行心跳续约时,Eureka会统计最近15分钟心跳失败的服务实例的比例是否超过了85%。在生产环境下,因为网络延迟等原因,心跳失败实例的比例很有可能超标,但是此时就把服务剔除列表并不妥当,因为服务可能没有宕机。Eureka就会把当前实例的注册信息保护起来,不予剔除。生产环境下这很有效,保证了大多数服务依然可用。
5、Ribbon负载均衡
选择哪一个服务,可以通过负载均衡控制,有轮询、随机等算法
可以修改负债均衡策略
Ribbon重试机制:
注册中心通常需要遵循CAP原则,CAP指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),往往三者不可兼得。
Eureka的服务治理主要强调是AP:即可用性和可靠性。
Eureka为了实现更高的服务可用性,牺牲了一定的一致性,极端情况下它宁愿接收故障实例也不愿丢掉健康实例,正如我们上面所说的自我保护机制。
但是,此时如果我们调用了这些不正常的服务,调用就会失败,从而导致其它服务不能正常工作!这显然不是我们愿意看到的。
Spring Cloud 整合了Spring Retry 来增强RestTemplate的重试能力,当一次服务调用失败后,不会立即抛出一次,而是再次重试另一个服务。
6、Hystix熔断器
Hystrix是Netflix开源的一个延迟和容错库,用于隔离访问远程服务、第三方库,防止出现级联失败。
使用熔断器Hystrix为了优化项目。
工作机制:
正常工作的情况下,客户端请求调用服务API接口:
当有服务出现异常时,直接进行失败回滚,00000000处理:
当服务繁忙时,如果服务出现异常,不是粗暴的直接报错,而是返回一个友好的提示,虽然拒绝了用户的访问,但是会返回一个结果。
这就好比去买鱼,平常超市买鱼会额外赠送杀鱼的服务。等到逢年过节,超时繁忙时,可能就不提供杀鱼服务了,这就是服务的降级。
系统特别繁忙时,一些次要服务暂时中断,优先保证主要服务的畅通,一切资源优先让给主要服务来使用,在双十一、618时,京东天猫都会采用这样的策略。
如果熔断和重试机制,都配置,是都生效?还是某个生效?
经测试发现是熔断生效,为什么?
1.Ribbon重试机制的超时时间设置的是1000ms:
2.Hystix的超时时间默认也是1000ms
3.实际执行后发现,没有触发重试机制,而是先触发了熔断。
所以,Ribbon的超时时间一定要小于Hystix的超时时间。
7、Feign服务调用
Feign是一种声明式、模板化的HTTP客户端。
在SpringCloud中使用Feign,我们可以做到使用HTTP请求远程服务时能与调用本地方法一样的编码体验,开发者完全感知不到这是远程方法,更感知不到这是个HTTP请求。
Feign的客户端
通过@FeignClient 声明Feign客户端。
value : 用于设置服务名称
path:用于设置路径前缀(也就是controller配置的路径)
Feign类似于MyBatis。
@FeignClient类似 @Mapper注解。
Feign中的方法需要与服务的方法声明完全一致。注意:路径
Feign会根据注解帮我们生成URL。
Feign中本身已经集成了Ribbon依赖,不需要额外引入依赖,就可以完成负载均衡处理。采用之前的配置就可以、
Feign默认也有对Hystix的集成,只不过,默认情况下是关闭的。
8、Zull网关
不管是来自于客户端(PC或移动端)的请求,还是服务内部调用。一切对服务的请求都会经过Zuul这个网关,然后再由网关来实现 鉴权、动态路由等等操作。Zuul就是我们服务的统一入口。
路由转发
路由前缀
过滤器:
Zuul作为网关的其中一个重要功能,就是实现请求的鉴权。而这个动作我们往往是通过Zuul提供的过滤器来实现的。
ZullFilter
ZuulFilter是过滤器的顶级父类。在这里我们看一下其中定义的4个最重要的方法:
public abstract ZuulFilter implements IZuulFilter{
abstract public String filterType(); //过滤器类型
abstract public int filterOrder(); //执行顺序
boolean shouldFilter(); //是否需要执行
Object run() throws ZuulException; //具体业务逻辑
}shouldFilter:返回一个Boolean值,判断该过滤器是否需要执行。返回true执行,返回false不执行。
run:过滤器的具体业务逻辑。
filterType:返回字符串,代表过滤器的类型。包含以下4种:
pre:请求在被路由之前执行
routing:在路由请求时调用
post:在routing和errror过滤器之后调用
error:处理请求时发生错误调用
filterOrder:通过返回的int值来定义过滤器的执行顺序,数字越小优先级越高。
过滤器执行生命周期
正常流程:
请求到达首先会经过pre类型过滤器,而后到达routing类型,进行路由,请求就到达真正的服务提供者,执行请求,返回结果后,会到达post过滤器。而后返回响应。
异常流程:
整个过程中,pre或者routing过滤器出现异常,都会直接进入error过滤器,再error处理完毕后,会将请求交给POST过滤器,最后返回给用户。
如果是error过滤器自己出现异常,最终也会进入POST过滤器,而后返回。
如果是POST过滤器出现异常,会跳转到error过滤器,但是与pre和routing不同的时,请求不会再到达POST过滤器了。
是用场景:
场景非常多:
请求鉴权:一般放在pre类型,如果发现没有访问权限,直接就拦截了
异常处理:一般会在error类型和post类型过滤器中结合来处理。
服务调用时长统计:pre和post结合使用。
负载均衡和熔断:
Zuul中默认就已经集成了Ribbon负载均衡和Hystix熔断机制。但是所有的超时策略都是走的默认值,比如熔断超时时间只有1S,很容易就触发了。因此建议我们手动进行配置
7、Sentinel
Sentinel :一个高可用的流量控制与防护组件,保障微服务的稳定性。
Sentinel分为两个部分,sentinel-core与sentinel-dashboard。
sentinel-core 部分能够支持在本地引入sentinel-core进行限流规则的整合与配置。
sentinel-dashboard 则在core之上能够支持在线的流控规则与熔断规则的维护与调整等。
8、Nacos
配置中心
9、Apollo配置中心

全部评论