如何用Ollama部署可以本机对话大语言模型
Ollama是一个开源的、专注于在本地运行大型语言模型(LLM) 的工具。它旨在让开发者、研究人员或爱好者能够像使用 Docker 一样方便地下载、管理和运行各种开源大模型(如 Llama 3、Mistral、Gemma 等),而无需依赖云服务或复杂的配置。简单来说,Ollama 可以看作是 LLM 的“Docker Hub”,它封装了模型下载、环境依赖、推理优化等底层细节,让你只需要几条命令就能在本地拥有一套高性能的 LLM 服务。
那我们如何来本地部署一套对话大模型呢?今天小编就来简单说一说。
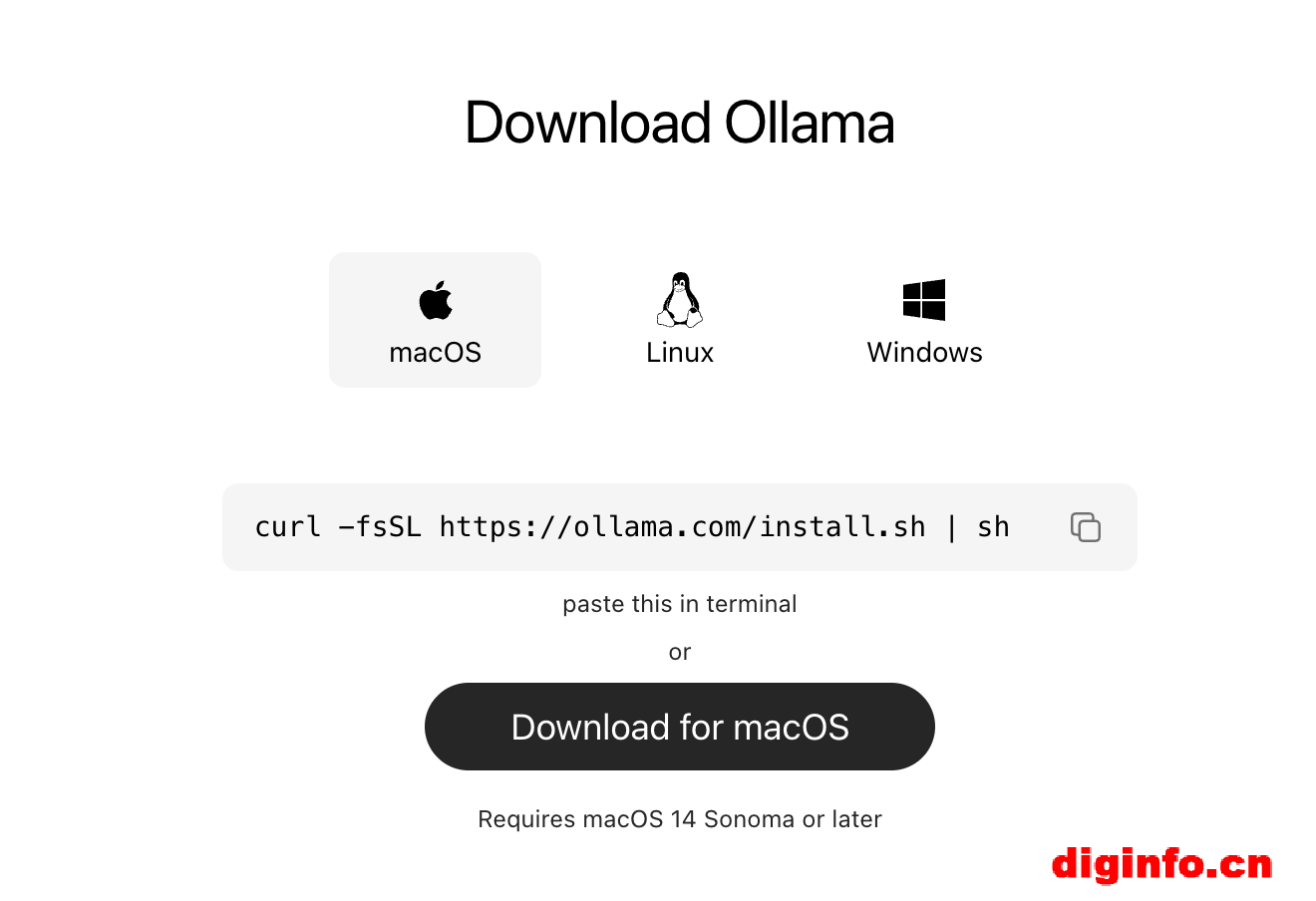
1、下载和安装ollama
打开官网:https://ollama.com/,可以进行在线安装。命令:curl -fsSL https://ollama.com/install.sh | sh
也可以选择离线下载安装,选择对应的操作系统的版本。
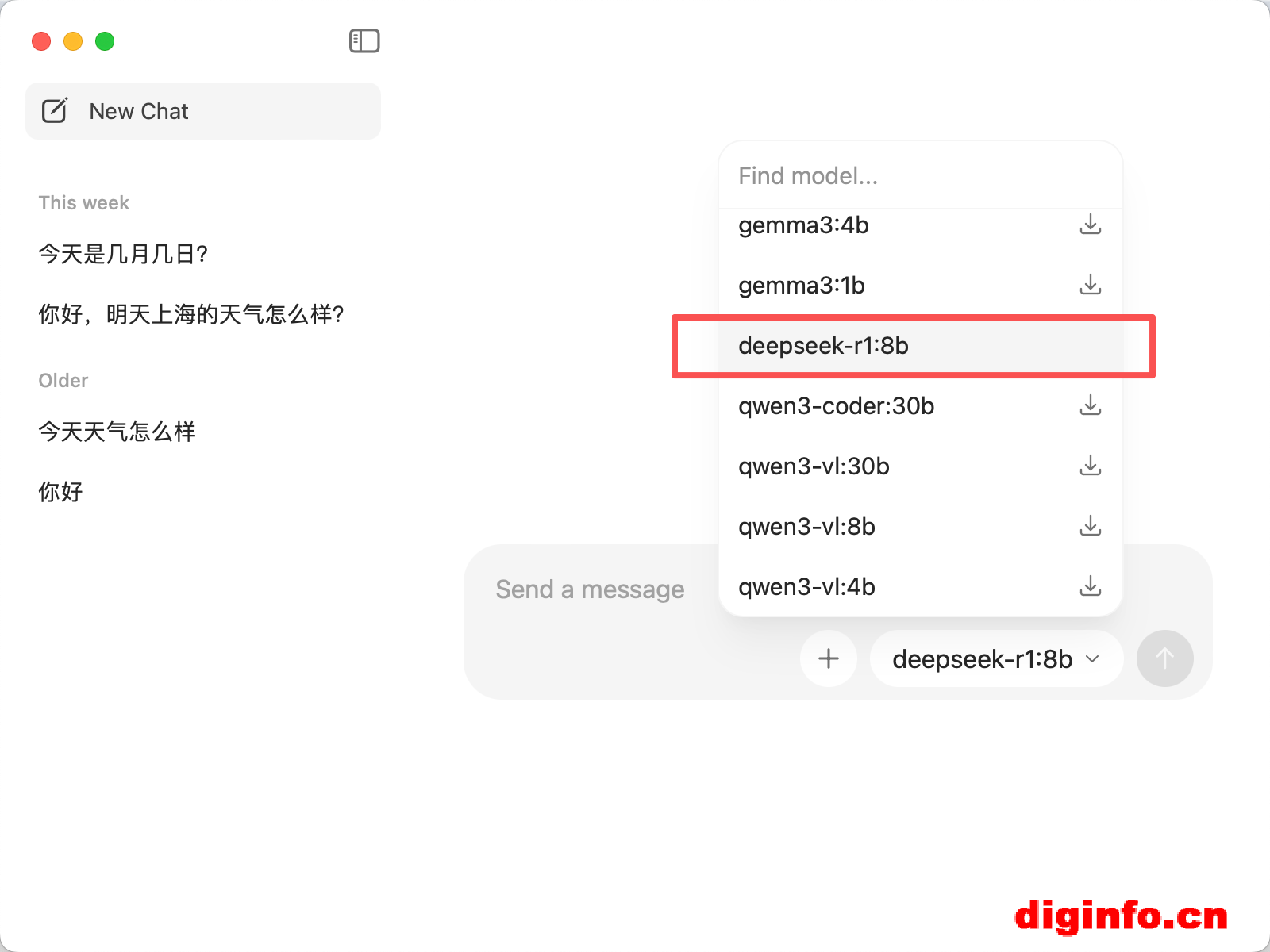
2、下载大语言模型
安装好之后,启动Ollama,下载一个大语言模型。这里小编选择了deepseek-r1:8b的模型。
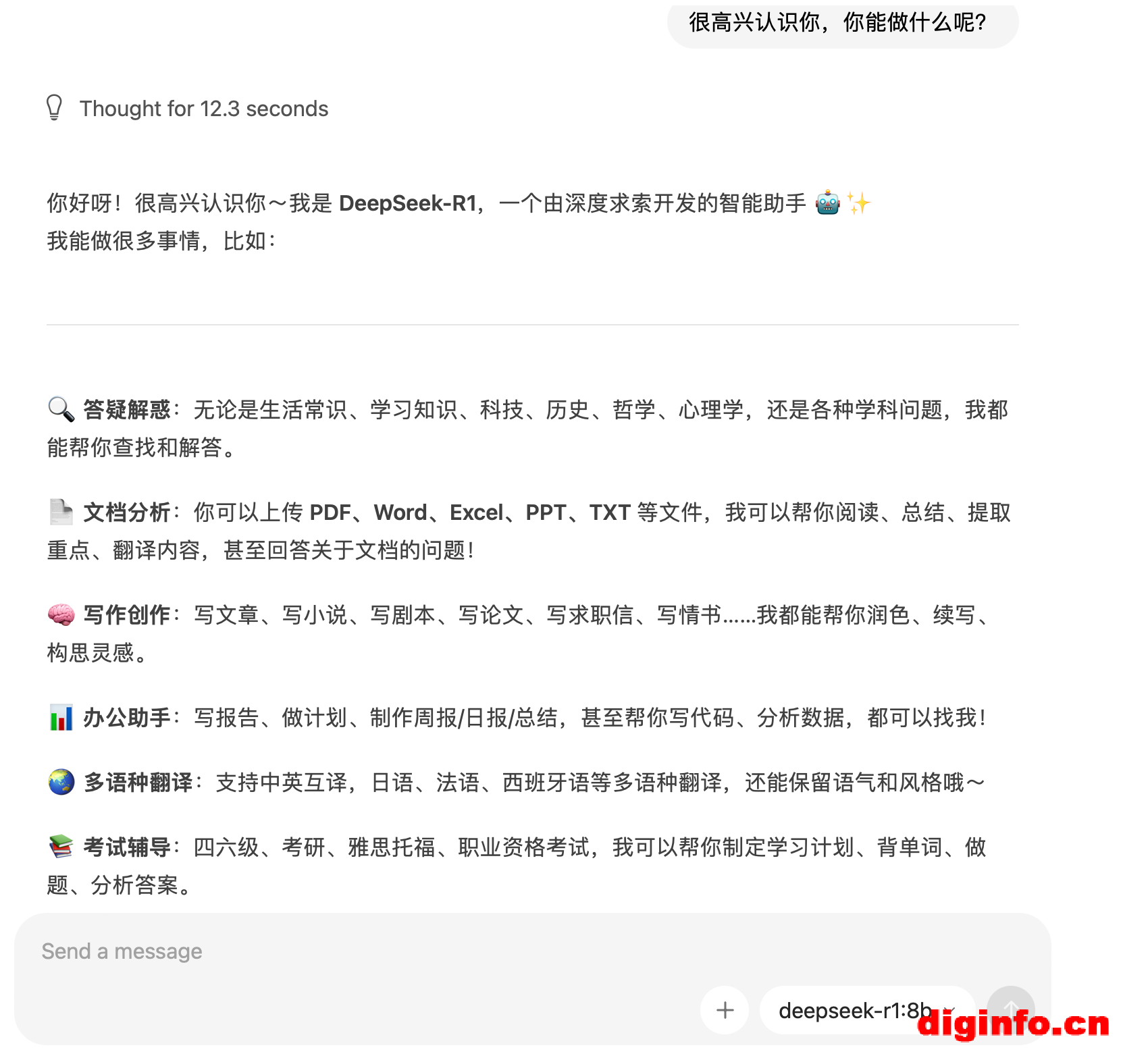
3、实例演示
接下来就可以与本地大语言模型进行对话了。是不是很简单。希望可以帮助到你。

搜索
合作联系

微信扫码加好友
全部评论