TensorRT + CUDA + DeepStream
TensorRT、CUDA 和 DeepStream 是 NVIDIA 为加速 AI 推理和视频流分析而设计的一套完整技术栈。简单来说,DeepStream 是一个基于 GStreamer 的智能视频分析框架,它利用 CUDA 在 GPU 上进行并行计算,并调用 TensorRT 对深度学习模型进行极致优化,从而构建出高性能的视频分析管道 。
为了帮助你更直观地理解这三者的关系,可以参考下面的示意图:
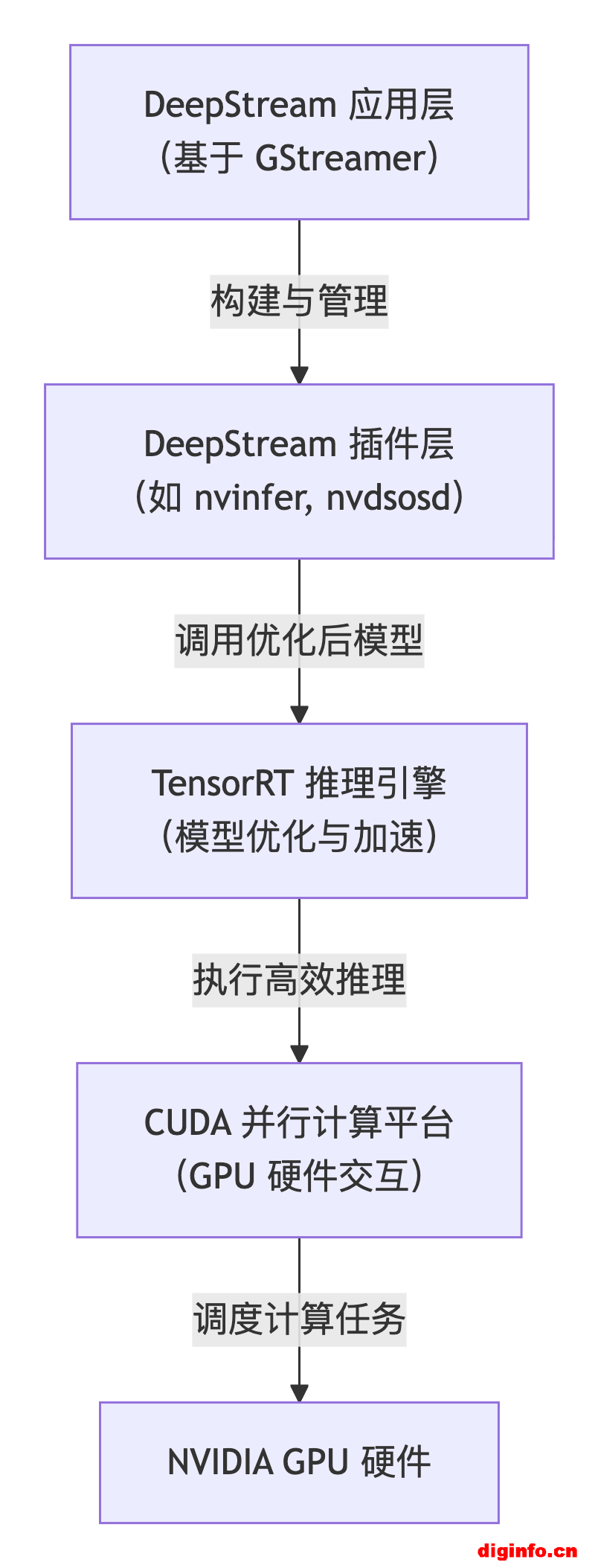
下面我们详细拆解这三者是如何在 DeepStream 中协同工作的:
🧠 TensorRT:高性能推理优化引擎
TensorRT 是 NVIDIA 专门用于高性能深度学习推理的优化器。在 DeepStream 管道中,它扮演着“性能核心”的角色 。
模型优化与部署:你可以将通过 TAO 工具套件训练或从其他框架(如 PyTorch、TensorFlow)导出的模型(如 .etlt 或 .onnx 格式),交给 DeepStream 的 nvinfer 插件。这个插件会在后台调用 TensorRT,对模型进行层间融合、精度校准(如 INT8)等优化,并生成一个针对当前 GPU 硬件高度优化的引擎文件 (.engine)。这个引擎文件才是最终被用来执行推理的 。
自定义支持:如果你的模型包含 TensorRT 原生不支持的层,DeepStream 也提供了接口,允许你通过 custom-lib-path 配置,以插件 (IPlugin) 的形式实现这些自定义层,确保任何复杂模型都能被优化 。
⚡ CUDA:并行计算基础平台
CUDA 是 NVIDIA 的通用并行计算平台,它提供了直接与 GPU 硬件交互的能力。在 DeepStream 中,CUDA 是支撑所有 GPU 加速功能的“地基” 。
数据零拷贝:DeepStream 最关键的优化之一就是避免不必要的数据复制。整个管道在 GPU 显存中共享数据缓冲区。解码后的视频帧直接存放在 GPU 显存中,后续的预处理、推理(通过 TensorRT)、跟踪等操作都通过指针直接访问这份数据,无需在 CPU 和 GPU 之间反复拷贝,极大地提升了吞吐量并降低了延迟 。
并行计算:除了推理,CUDA 还被用于加速 DeepStream 管道中的其他计算密集型任务,例如图像预处理(缩放、色彩空间转换)、多流视频的解码和编码等 。
📦 DeepStream:智能视频分析框架
DeepStream 本身是一个基于 GStreamer 的完整的流式分析软件开发工具包。它就像一个智能的“装配车间”,将 TensorRT 和 CUDA 的能力整合成一个模块化、可配置的管道 。
插件化管道:DeepStream 的核心是一系列 GStreamer 插件。你可以像搭积木一样将它们连接起来,形成一个处理流程 。例如:
Gst-nvstreammux 将多个输入流合并成一个批次。
Gst-nvinfer 插件是这个管道中的“大脑”,它正是我们上面提到的,负责调用 TensorRT 引擎进行推理的部分 。
Gst-nvtracker 在推理结果的基础上进行目标跟踪。
Gst-nvdsosd 将推理得到的边界框、标签等信息绘制在视频帧上。
统一的内存管理:DeepStream 框架利用 CUDA 管理了一套统一的显存池,确保了数据在不同插件间传递时,传递的只是指针,而非实际数据,从而实现了高效的内存共享 。
💡 典型应用流程
一个典型的基于这三者的应用开发流程如下:
训练模型:使用你喜欢的框架训练一个模型(例如,用于检测车辆和行人的模型)。
模型导出与优化:将模型导出为通用格式(如 ONNX),或者直接使用 TAO 工具套件导出为 .etlt 格式 。
配置 DeepStream 管道:编写 DeepStream 的配置文件(如 config_infer_primary.txt),在其中指定模型路径、TensorRT 引擎生成选项(精度、批量大小等)以及自定义解析库路径(如果输出需要特殊解析)。
首次运行:DeepStream 应用首次启动时,nvinfer 插件会自动调用 TensorRT 解析模型并生成针对你当前 GPU 优化的引擎文件。这个过程可能需要几分钟 。
部署运行:引擎文件生成后,再次运行 DeepStream 应用,它将直接加载这个引擎文件,以最优性能对输入的视频流进行实时分析。
总的来说,这三者的关系可以这样理解:CUDA 是 GPU 计算的基石,TensorRT 是基石上最高效的推理引擎,而 DeepStream 则是集成这两者、专为视频流分析场景设计的流水线作业平台。


微信扫码加好友
全部评论