OpenCV开发教程之FLANN特征匹配
FLANN (Fast Library for Approximate Nearest Neighbors) 是 OpenCV 中用于大规模特征点快速近似匹配的工具。与暴力匹配的全局穷举不同,FLANN 通过构建高效的索引树,在可接受的精度损失下,将匹配时间大幅缩短,尤其适合特征点数量成千上万的场景。
1. FLANN 匹配器的核心原理
FLANN 会先对训练描述子集建立索引(如 k-d 树、k-means 树或 LSH),查询时利用树结构快速定位近邻,避免逐个比较。默认情况下,它寻找的是近似最近邻,速度远快于 BFMatcher。
OpenCV 将其封装为 cv::FlannBasedMatcher,用法和 BFMatcher 几乎一模一样,同样支持 match() 和 knnMatch()。
2. 重要注意事项
描述子数据类型
浮点型(SIFT、SURF、K-AZE):默认 CV_32F,直接用 FlannBasedMatcher()。
二进制(ORB、BRISK、BRIEF):CV_8U,必须提供 LSH 索引参数,否则报错。
FLANN 不适合过小的数据集
特征点少于几百时,构建索引的开销可能大于节省的搜索时间,此时暴力匹配反而更快。
近似匹配 vs 精确匹配
默认情况下 FLANN 返回近似最近邻,精度略低于暴力匹配,但通过增大 checks / trees 等参数可以逼近暴力匹配的结果。
内存与训练FlannBasedMatcher 有一个 add() / train() 过程,若多次使用同一训练描述集,可以手动调用 flann.add(des2)、flann.train() 预训练索引以加速后续多次匹配。
3. FLANN vs. BFMatcher 对比
| 特性 | BFMatcher | FlannBasedMatcher |
|---|---|---|
| 搜索方式 | 全局穷举 | 基于树 / LSH 索引的近似搜索 |
| 时间复杂度 | O(N²) | 对数级别,大规模时优势明显 |
| 是否精确 | 精确最近邻 | 近似最近邻(可调节到接近精确) |
| 适用描述子 | 所有类型,只需指定距离度量 | 浮点型直接支持;二进制需配置 LSH |
| 推荐场景 | 特征点 < 几千 | 特征点 > 几千 |
| 参数调优 | 极少(仅交叉检验) | 需根据数据调节索引和搜索参数 |
4. 小结
FLANN 是 OpenCV 中处理大规模特征匹配的高效工具:
用 cv2.FlannBasedMatcher 替换 BFMatcher,其余流程不变。
浮点描述子可直接使用默认参数;二进制描述子务必提供 LSH 索引参数。
结合 Lowe’s 比率测试(knnMatch(k=2))可得到高质量匹配。
当你的项目从几十个特征点进化到几千甚至几万时,将 BFMatcher 切换到 FlannBasedMatcher 就是几乎零成本的性能升级。
# FLANN特征匹配
# FLANN是快速最近邻搜索包(Fast Library for Approximate Nearest Neighbors) 的简称。它是一个对大数据集和高维特征
# 进行最近邻搜索的算法的集合,而且这些算法都已经被优化过了。在面对大数据集时它的效果要好于BFMatcher。
# 特征匹配记录下目标图像与待匹配图像的特征点(KeyPoint),并根据特征点集合构造特征量(descriptor)对这个特征量进行比较、
# 筛选,最终得到一个匹配点的映射集合。我们也可以根据这个集合的大小来衡量两幅图片的匹配程度。
# FlannBasedMatcher(inidex_params)
# o index_params字典:匹配算法KDTREE, LSH, SIFT和SURF使用KDTREE算法,OBR使用LSH算法
# .设置示例: index_params=dict(algorithm=cv2.FLANN_INDEX_KDTREE, tree=5)
# .FLANN_INDEX_LSH = 6index_params= dict(algorithm = FLANN_INDEX_LSH, table_ number= 6,
# # 12 key size = 12, # 20 multi probe level = 1#2)
# osearch params字典:指定KDTREE算法中遍历树的次数.经验值,如KDTREE设为5,那么搜索次数设为50.- search_params = dict(checks=50)Flann中除了普通的match方法,还有knnMatch方法.
# 多了个参数--k,表示取欧式距离最近的前k个关键点
实例代码如下:
import cv2
print(cv2.getVersionString())
import numpy as np
from utils import plt_showimg
img1 = cv2.imread('./images/opencv1.png')
img2 = cv2.imread('./images/opencv2.png')
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# 创建特征检测对象
sift = cv2.SIFT_create()
#计算描述子
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
# 创建特征匹配对象
# print('cv2.FLANN_INDEX_KDTREE:', cv2.FLANN_INDEX_KDTREE)
# index_params = dict(algorithm=cv2.FLANN_INDEX_KDTREE, tree=5)
index_params = dict(algorithm=1, tree=5)
#根据经验,kdtree设置5个tree,那么checks一般设置为50次
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
# matches = flann.knnMatch(des1, des2, k=2)
matches = flann.match(des1, des2)
print(len(matches))
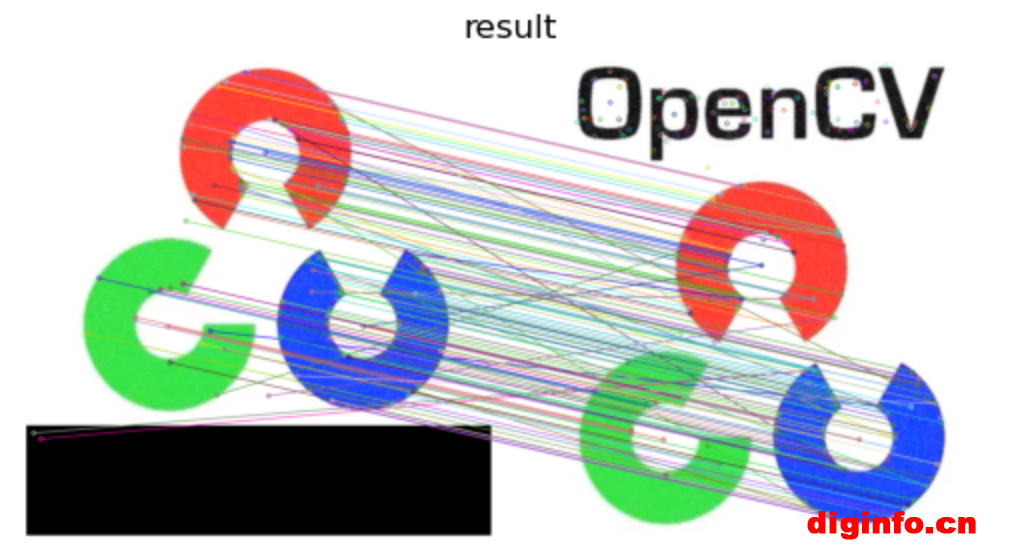
result = cv2.drawMatches(img1, kp1, img2, kp2, matches, None)
# 显示结果
plt_showimg(result, 'result')
效果图展示如下:


微信扫码加好友
全部评论